Recent Gains from reading research papers[Oct 13th]
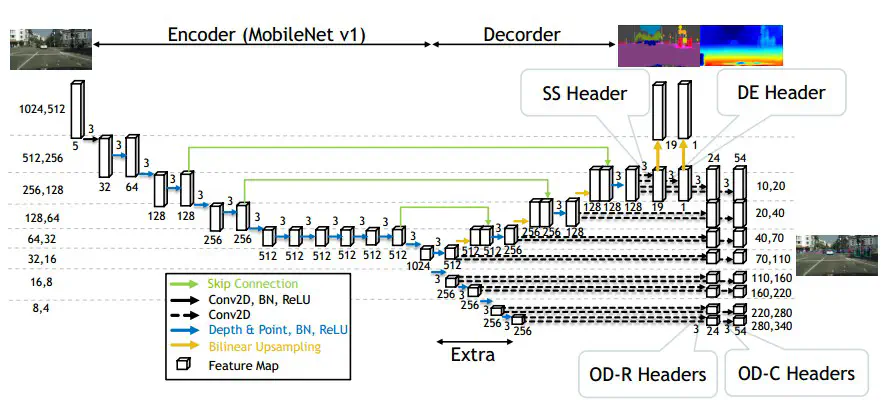 Image credit: Unsplash
Image credit: Unsplash
[1] Miyama M. Robust inference of multi-task convolutional neural network for advanced driving assistance by embedding coordinates[C]//Proceedings of the 8th World Congress on Electrical Engineering and Computer Systems and Science, EECSS. 2022: 105-1.
This paper develops a multi-task CNN (Convolutional Neural Network) for advanced driver assistance. The network performs three tasks simultaneously: object detection, semantic segmentation and parallax estimation. The innovation is that the three tasks share not only an encoder but also a decoder. The decoder uses a combination of deep point-by-point convolution and bilinear interpolation instead of the common transposed convolution. The number of multiply-accumulate operations can be reduced to 44.0% and the number of convolutional weight parameters to 38.2%. In multi-task CNN training, the loss weights for each task are automatically adjusted by backpropagation, and the three tasks are learned in a balanced manner. Reducing the complexity of the decoder not only did not reduce the recognition accuracy, but also improved it.
Note1: The combination of DP convolution and bilinear interpolation instead of the normal transposed convolution of the decoder reduces the number of parameters while maintaining the accuracy, which can be borrowed in the subsequent lightweighting algorithms done.
Note2: In the experimental session, without input coordinates, semantic segmentation and parallax estimation would be incorrectly estimated at the same location. The possible reason for this is that both tasks are the result of the inference of a CNN. the CNN uses a monocular image to estimate parallax. In this case, the parallax estimation depends on the type, size and location of the object. Therefore, there is a strong correlation between semantic segmentation and parallax estimation.
Note3: FlowNet for optical flow estimation can also be used for stereo vision parallax estimation. The encoder extracts feature maps from a pair of two images while gradually decreasing the resolution, and the decoder generates a per-pixel motion flow from the encoded feature maps while gradually increasing the resolution.
Tianxiong Zhang
My research interests include Digital Twin, Computer Vision, Urban Air Mobility (UAM).