Recent Gains from reading research papers[Mar 15th]
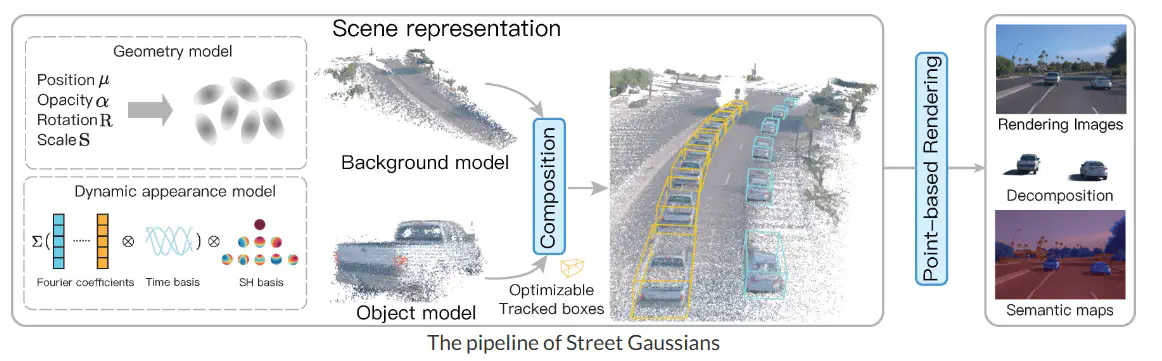 Image credit: Unsplash
Image credit: Unsplash
[1] Yan Y, Lin H, Zhou C, et al. Street gaussians for modeling dynamic urban scenes[J]. arXiv preprint arXiv:2401.01339, 2024.
This paper introduces a novel scene representation method termed “Street Gaussians,” designed for modeling dynamic urban street scenes from monocular video data. This approach addresses the limitations of existing technologies characterized by slow training and rendering speeds, as well as a heavy reliance on precise tracking of vehicular poses. Street Gaussians overcome these constraints by explicitly representing dynamic urban streets with point clouds, semantic logits, and 3D Gaussians. The method is capable of completing training within half an hour and rendering high-quality images at a rate of 133 frames per second.
Note1: The three-dimensional reconstruction of autonomous driving scenes for simulation environment construction leverages the creation of realistic urban street scenes to provide a virtual testing ground for autonomous vehicles, thereby reducing the costs and risks associated with real-vehicle testing. By generating high-quality virtual images and point cloud data, this technology aids in the development and training of sensor fusion algorithms within autonomous driving systems, such as the integration of data from radar, LiDAR, and cameras. It also enhances the scene understanding of autonomous vehicles, including vehicle detection, pedestrian recognition, and traffic sign interpretation, thus supporting more accurate and reliable decision-making.
Note2: The innovation of the article lies in its adoption of an explicit scene representation, wherein dynamic urban streets are depicted as a collection of point clouds with semantic logits and 3D Gaussians, simulating foreground vehicles or the background. This explicit representation allows for the easy combination of object vehicles and the background, facilitating scene editing operations, and is capable of completing training in half an hour, achieving real-time rendering. Moreover, to simulate the dynamics of foreground object vehicles, each object point cloud is optimized through an adjustable tracking pose, combined with a dynamic spherical harmonics model to handle dynamic appearances. This representation method allows for the use of poses provided by off-the-shelf trackers, achieving performance comparable to that using precise ground truth poses, even in the presence of noisy data.
Note3: Applying this technology to the apron, we can not only create finely detailed and lifelike apron scenes but also dynamically generate traffic flow within the apron, realizing a realistic digital twin platform. This platform can be used for the verification of various algorithms during the mixed operation of manned/unmanned vehicles.
Tianxiong Zhang
My research interests include Digital Twin, Computer Vision, Urban Air Mobility (UAM).