Recent Gains from reading research papers[June 30th]
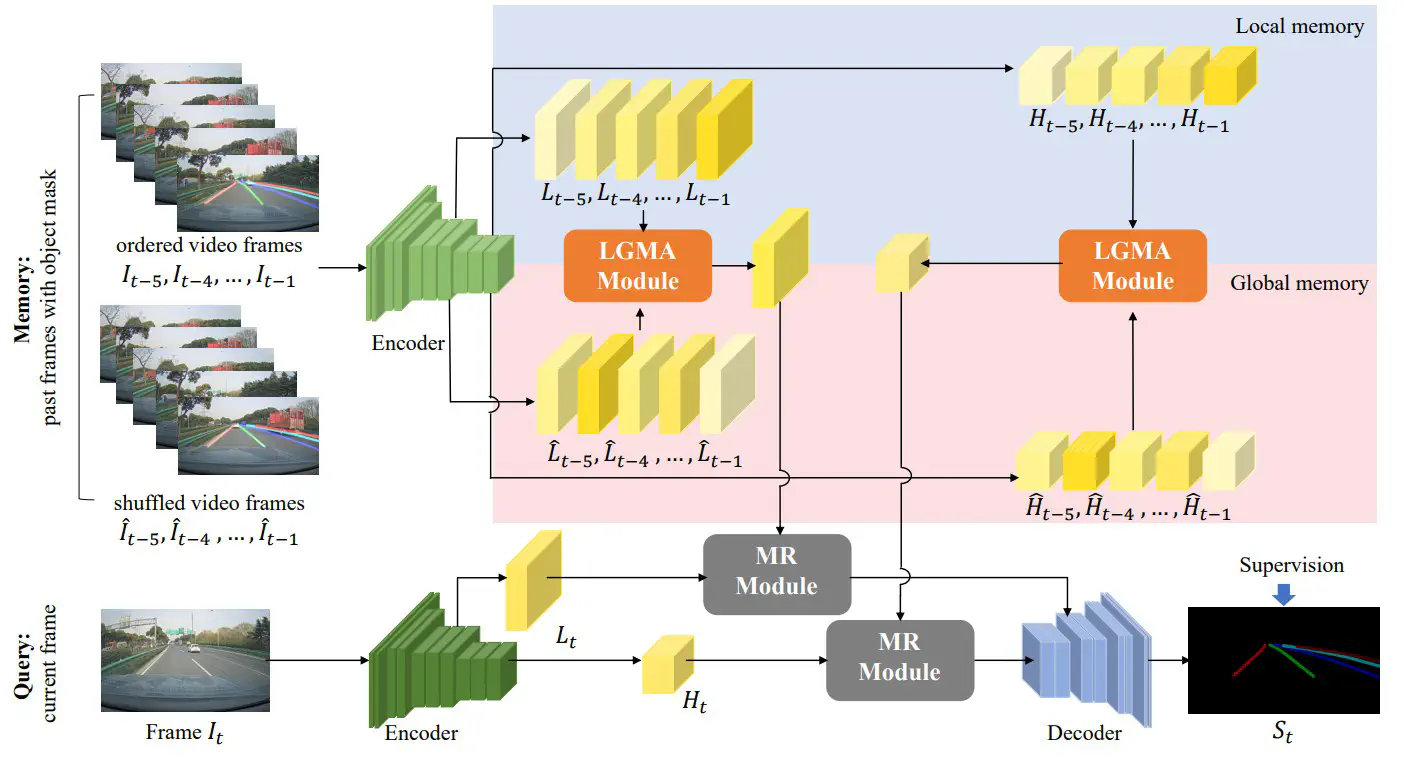 Image credit: Unsplash
Image credit: Unsplash
[1]Zhang Y, Zhu L, Feng W, et al. Vil-100: A new dataset and a baseline model for video instance lane detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15681-15690.
Lane detection in current research focuses on individual images (frames) and ignores the information available in continuous video. Instead, this thesis establishes a new video instance lane detection (VIL-100) dataset. In addition a new baseline model is proposed. Its main focus is to enhance the representation of the current frame by carefully aggregating local and global memory features from other frames.
Note 1:
Note 1: Extending deep learning-based lane detection from the image level to the video level can utilize temporal consistency to solve many intra-frame blurring, occlusion, and misrecognition problems. Similarly, this idea can be applied to intra-airport recognition. Specifically, the past frames of the original video can be formed into a local memory, the past frames of the mixing-sorting video can be used as a global memory, and the current video frame can be segmented and globally memorized as a query using features extracted from the video frames in the local memory. These multi-level memory features are aggregated by designing Local and Global Memory Aggregation (LGMA) modules, and then all CNN features are integrated together to produce video detection results.
Note 2:
Note 2: Existing memory networks utilize periodic sampling per N frames to include both near and far frames, but all sampled frames are ordered and extracted features may depend heavily on temporal information. In contrast, the LGMA module designed in this dissertation can utilize five frames from a shuffled video in global memory to eliminate temporal ordering and enhance the global semantic information used to detect lanes. Since the content differs for video frames, memory features from different frames will have different contributions to help the current video frame recognize the background object. Therefore, the attention mechanism can be utilized to learn the attention graph in order to automatically assign different weights to local memory features and global memory features.
Note 3:
A lane annotation method: a series of points are placed along the centerline of each lane in each frame and they are stored in a json format file. The points on each lane are stored in one group. Each set of points is then fitted to a curve by a third-order polynomial and expanded into a region of lanes with a certain width, thus enabling instance-level annotation.
Tianxiong Zhang
My research interests include Digital Twin, Computer Vision, Urban Air Mobility (UAM).