Recent Gains from reading research papers[Dec 22th]
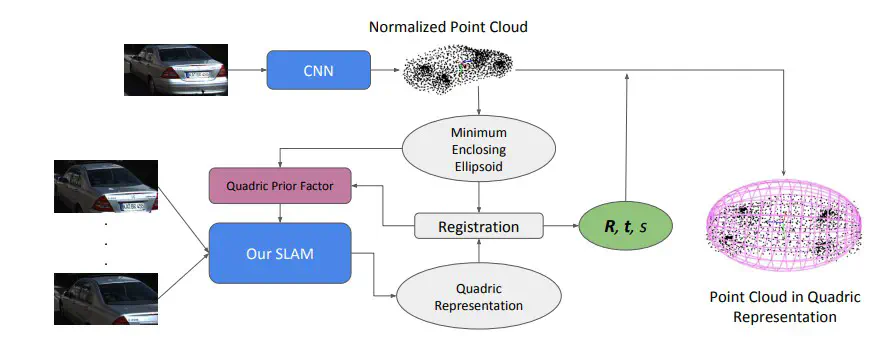 Image credit: Unsplash
Image credit: Unsplash
[1] Hosseinzadeh M, Li K, Latif Y, et al. Real-time monocular object-model aware sparse SLAM[C]//2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019: 7123-7129.
The article constructs a Semantic SLAM based on sparse point clouds, integrating real-time deep learning object detection with a monocular SLAM framework. This achieves a secondary surface representation for general objects and ensures real-time performance. The work is primarily based on the traditional ORB-SLAM algorithm, incorporating CNN networks to finely reconstruct identified targets and providing shape priors for secondary surfaces. To capture the main structure of the scene, additional plane landmarks are detected through a CNN-based plane detector and modeled as independent landmarks in the map.
Note1: The innovation of the paper lies in the use of sparse point clouds, unlike conventional Object-SLAM that often relies on dense point clouds. By merging the object detector, the paper achieves dense reconstruction of identified objects, realizing Semantic SLAM while significantly reducing computational complexity. Additionally, the article utilizes a CNN network to extract plane information. Data association between planes is mainly obtained through shared keypoints, normals, and distance relationships. An added object point cloud generation network places specific object detection boxes into a CNN network, generating a point cloud to represent the 3D shape of the object, then estimating alignment parameters with the ellipsoid in SLAM after normalizing the bounding ellipsoid. The generated object point cloud can be used to provide object shape priors, introducing additional constraints in optimization.
Note2: Previous representations of dual quadric surfaces for general objects had certain constraints: (1) From the frontend perspective, such as a) dependence on the depth channel for plane segmentation and parameter regression, b) precomputation of object detection based on Faster R-CNN to allow real-time performance, and c) self-organized object and plane matching/tracking. (2) From the backend perspective: a) assuming conic observations are axis-aligned, limiting the robustness of quadric surface reconstruction, b) keeping all detected landmarks in a single global reference frame. This work not only addresses the aforementioned constraints but also introduces new factors applicable to real-time inclusion of planes and object detection while integrating detailed point cloud reconstruction from deep learning CNN into the map. The algorithm’s final output remains quadric surface bounding boxes, and future work may consider further constraint elimination using more precise expressions.
Tianxiong Zhang
My research interests include Digital Twin, Computer Vision, Urban Air Mobility (UAM).